Questions
I came up with the questions of
- How many daily active users? (DAU)
- What are the latency requirements?
these were some additional suggested questions
- What features should we focus on?
- What modes of traffic do we need to support?
- How about business places and photos?
- Do we need to support multi-stop locations?
Design
On a high level, this is the design of the system that will support our goal
We need two main services
-
Location Service : Keeps track of a user’s position
-
Navigation Service : Given a user’s location and information on existing road conditions, suggests a route for users to follow
Client
Our client is responsible for rendering the map using map tiles. By choosing the set of tiles appropriate for the zoom level of the map, the client can render a map of the world for use.
We utilise a CDN to serve up pre-generated images of our tiles. In the event that we have a cache miss, then we want to generate these tiles.

It is more efficient to utilise a combination of a service + a CDN for a user since this gives us more fine-grained control over the generation of URLs.
If we assume we serve about 5 billion minutes of navigation a day, this translates to 62,500 MB (6.25 billion / 10^5 seconds in a day) of map data per second. With a CDN, these map images are going to be served from the POPs all over the world. Let’s assume there are 200 POPs. Each POP would only need to serve a few hundred MBs (62,500 / 200) per second.
Data can be cached on the CDN using the geohash of the tile.
Location Service
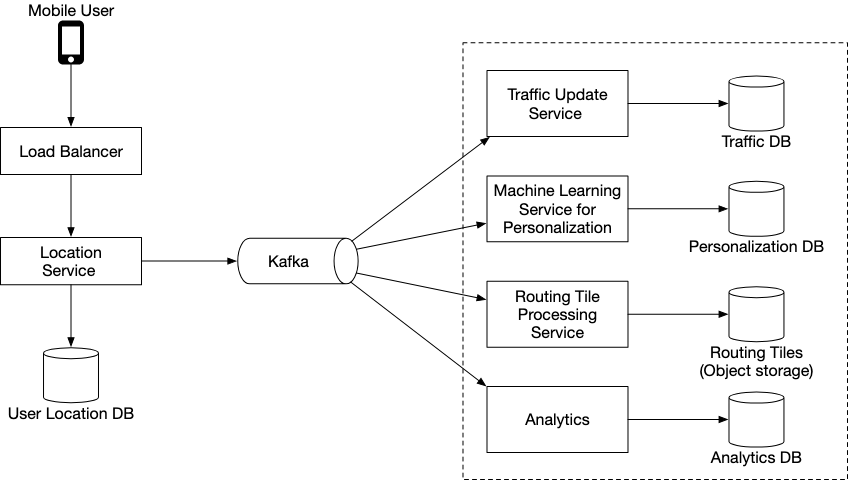
Our location service has the following components
-
User Location DB : This should take the form of a No-SQL database with the user_id as a key. This will allow us to support large amounts of concurrent writes to the db
-
Kafka : We utilise a Kafka pipeline so that we route any new updates to other downstream systems. These systems could potentially be used to personalise recommendations, detect new and closed road and more.
User Location DB
One database that is a good fit is Cassandra. It can handle our scale with a strong availability guarantee. The key is the combination of (user_id, timestamp) and the value is a lat/lng pair. In this setup, user_id is the primary key and timestamp is the clustering key. The advantage of using user_id as the partition key is that we can quickly read the latest position of a specific user. All the data with the same partition key are stored together, sorted by timestamp.
| key (user_id) | timestamp | lat | long | user_mode | navigation_mode |
|---|---|---|---|---|---|
| 51 | 132053000 | 21.9 | 89.8 | active | driving |
Batching
If we assume that we have around 1 billion users who are each using the application for 35 minutes per week, or around 5 minutes per day, we have around 7 billion requests a day if we update the user’s request every second.
A smarter way is to instead use batching, where we capture the user’s location every second but send the information over in a batch of 15 snapshots.
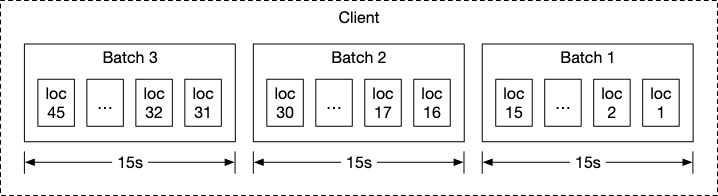
Navigation Service
Routing Tiles
We utilise a modified A* path-finding algorithm in order to determine the best path for the user given a start and end location. One way we do so is by using a tiling concept, where we represent each individual area using a graph.
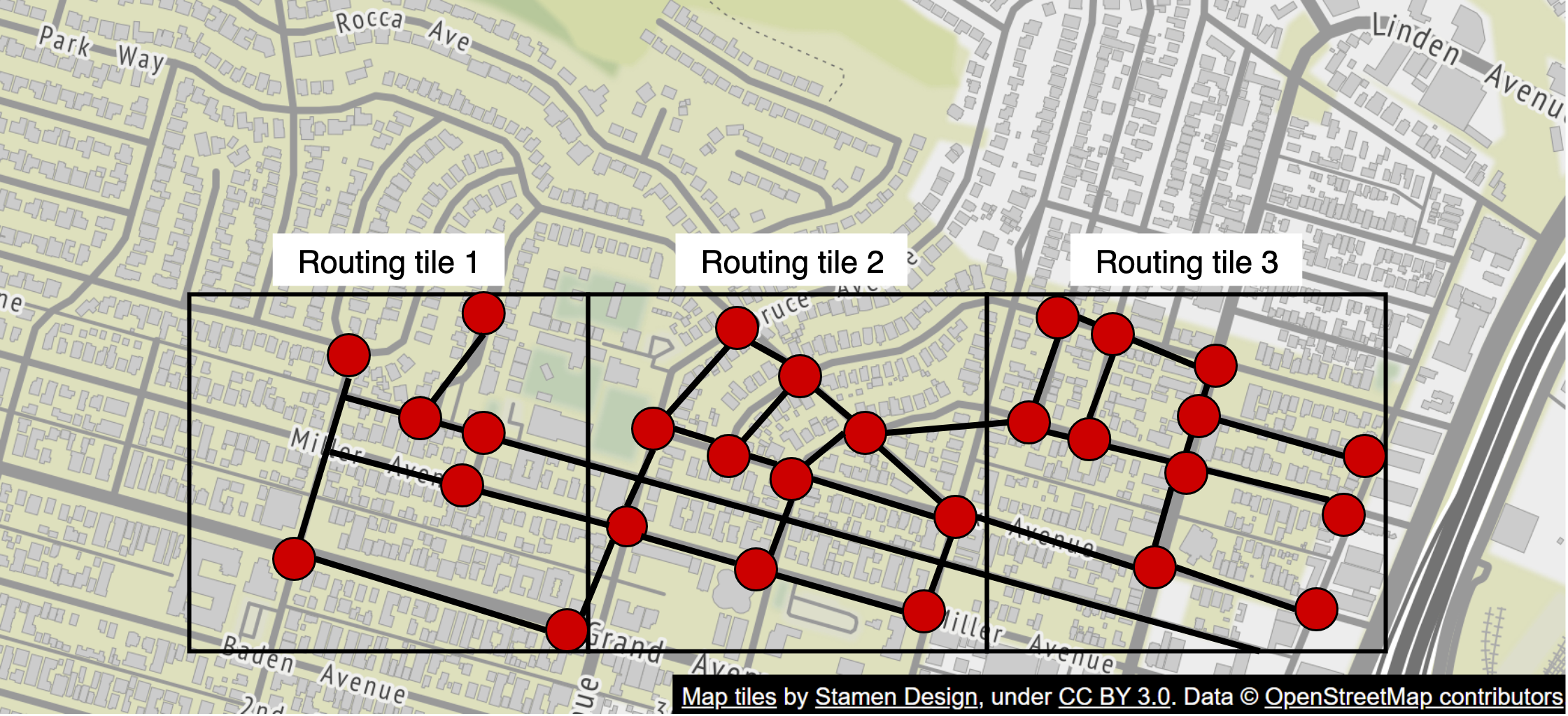
By breaking up the road network into routing tiles, the routing algorithm can improve the performance by only consuming a small subset of the tiles at a time, and only loading additional tiles as needed.
These routing tiles are typically organised in a 3-tier hierarchy
- Local Roads : Smallest and lowest level of the hierarchy
- Arterial Roads : Second tier which shows the larger roads connecting these larger roads
- Highways : These cover significantly larger areas and only contain the major highways connecting the cities together.
At each level, we have edges connecting to tiles at a different zoom level.
Resource Utilisation
We need to store three types of data.
- Map of the world: A detailed calculation is shown below.
- Metadata: Given that the metadata for each map tile could be negligible in size, we can skip the metadata in our computation.
- Road info: The interviewer told us there are TBs of road data from external sources. We transform this dataset into routing tiles, which are also likely to be terabytes in size.
The number of tiles required at each zoom level is where is the level of zoom. We can roughly see the progression below
| Zoom | Number of Tiles |
|---|---|
| 0 | 1 |
| 1 | 4 |
| 2 | 4 |
| … | … |
| 19 | 274,877,906,944 |
| 20 | 1,099,511,627,776 |
| 21 | 4,398,046,511,104 |
At the highest level, assuming each tile takes 100kb of space, we need approximately 400 PB
Since 90% of the world’s surface is natural and uninhabited, we can conservatively reduce the amount of space required by ~80%-90%. This would reduce the storage size to around 44 to 88 PB.
Each time we reduce our zoom size, the amount of space required drops by 4x, so we need approximately
which is approximately 67 PB.
Concepts
CAP
The CAP theorem states that we can only choose two attributes from the following three in any distributed system - consistency, availability and partition tolerance. Since partition tolerance is inherent in any distributed system, this means that we have to choose between a consistent system or an available system.
An available system will always process requests, even if the data is not consistent with the rest of the system. In such a case, we might have eventual consistency instead of strong consistency.
A consistent service will instead hold off on processing requests or even reject requests until all services within the system are synchronised with the same data
Given the fact we have 1 million location updates every second, we need to have a database that supports fast writes. A No-SQL key-value database or column-oriented database would be a good choice here. In addition, a user’s location is continuously changing and becomes stale as soon as a new update arrives. Given our constraints, we would go with availability and partition tolerance.
Apache Cassandra
Cassandra: Apache Cassandra is a highly scalable, distributed, and fault-tolerant NoSQL database designed to handle large amounts of data across many nodes. It provides high availability with no single point of failure and is widely used for its performance and scalability
-
Partition key: In Cassandra, the partition key is a part of the primary key that determines which node stores the data. It is responsible for distributing data evenly across the nodes in a cluster. The partition key can be a single column or a composite of multiple columns. In the paragraph you provided, the user_id is the partition key, which means that data will be distributed based on the user’s ID.
-
Clustering key: The clustering key is another part of the primary key in Cassandra, which determines the order of data within each partition. Clustering keys are used to sort data within a partition for efficient retrieval of similar values. In the paragraph, the timestamp is the clustering key, which means that data within each partition (i.e., for each user) will be sorted by the timestamp.
In the given setup, the primary key is a combination of user_id (partition key) and timestamp (clustering key). The advantage of using user_id as the partition key is that it allows for quickly reading the latest position of a specific user, as all the data with the same partition key are stored together and sorted by timestamp
Routing Tiles
Google Maps uses a modified Mercator Projector which will transpose a 3D sphere onto a 2D space. By projecting our map onto a 2D space, we can then recursively compose our map using a geohash.
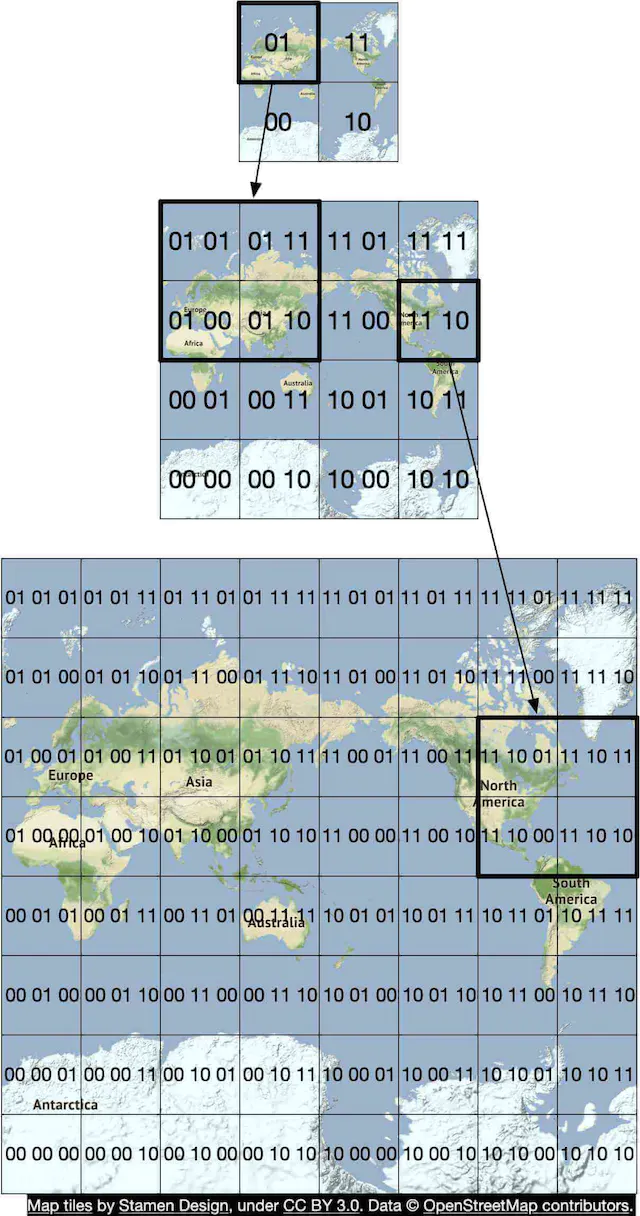
By using these geohashes, we can break down the larger world map into smaller tiles.