Concepts
Case Studies
Here are some case studies where we try to follow the System Design Interview Framework
- Design A Rate Limiter
- Design A Key-Value Store
- Design a Unique ID Generator for a Distributed System
- Design a URL Shortener
- Design a Web Crawler
- Design a Notification System
- Design a News Feed
- Design a Chat System
- Design a Search Autocomplete System
- Design Youtube
- Design Google Drive
- Design Proximity Service
- Design Nearby Friends
- Design Google Maps
- Design a Message Queue
- Design a Metrics Monitoring and Alerting System
- Ad Click Event Aggregation
- Hotel Reservation System
- Design a Email System
Components of An Application
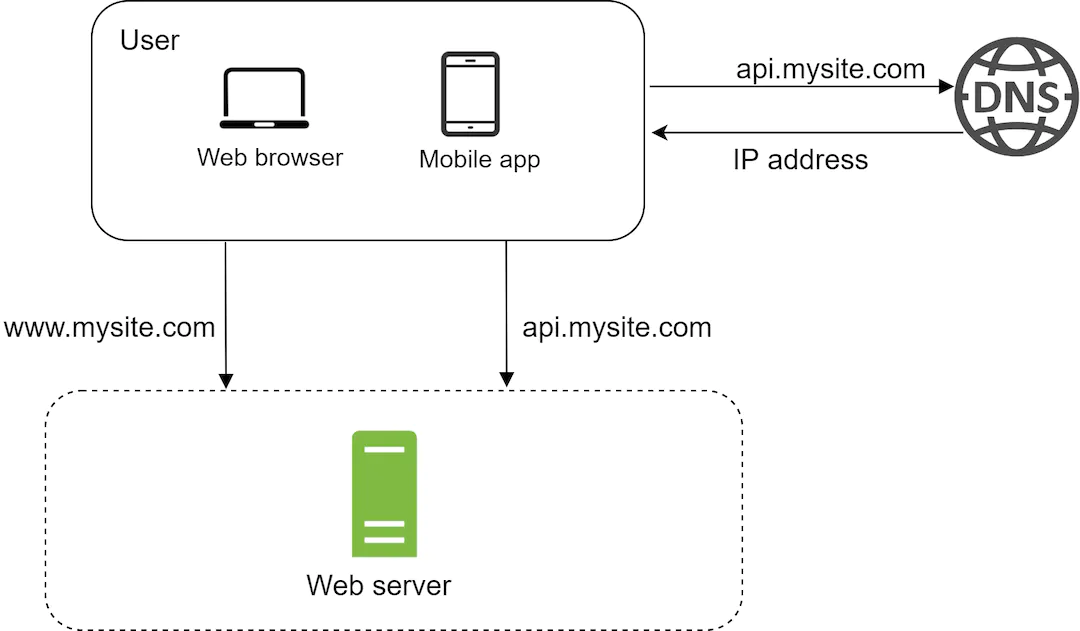
DNS
A DNS is used to resolve a website address (Eg. www.google.com ) to a concrete IP Address
Our browser will hit a browser in order to get back an IP to forward an address to. Typically a DNS is a service provided by another service (Eg. Cloudflare )
Servers
Our application then hit the servers and get back either HTML or JSON content and renders it on the screen
Scaling
When we scale our servers, we have two choices - Vertical Scaling or Horizontal Scaling. Vertical Scaling involves increases the hardware that our server is hosted upon while horizontal scaling involves increasing the number of instances of the server.
Statefulness
Our servers are stateful if they hold access to some unique form of information on the servers instead of storing it in some stateful store. The following is an example of a stateless architecture where user sessions are stored in a common data store rather than on the server process itself.
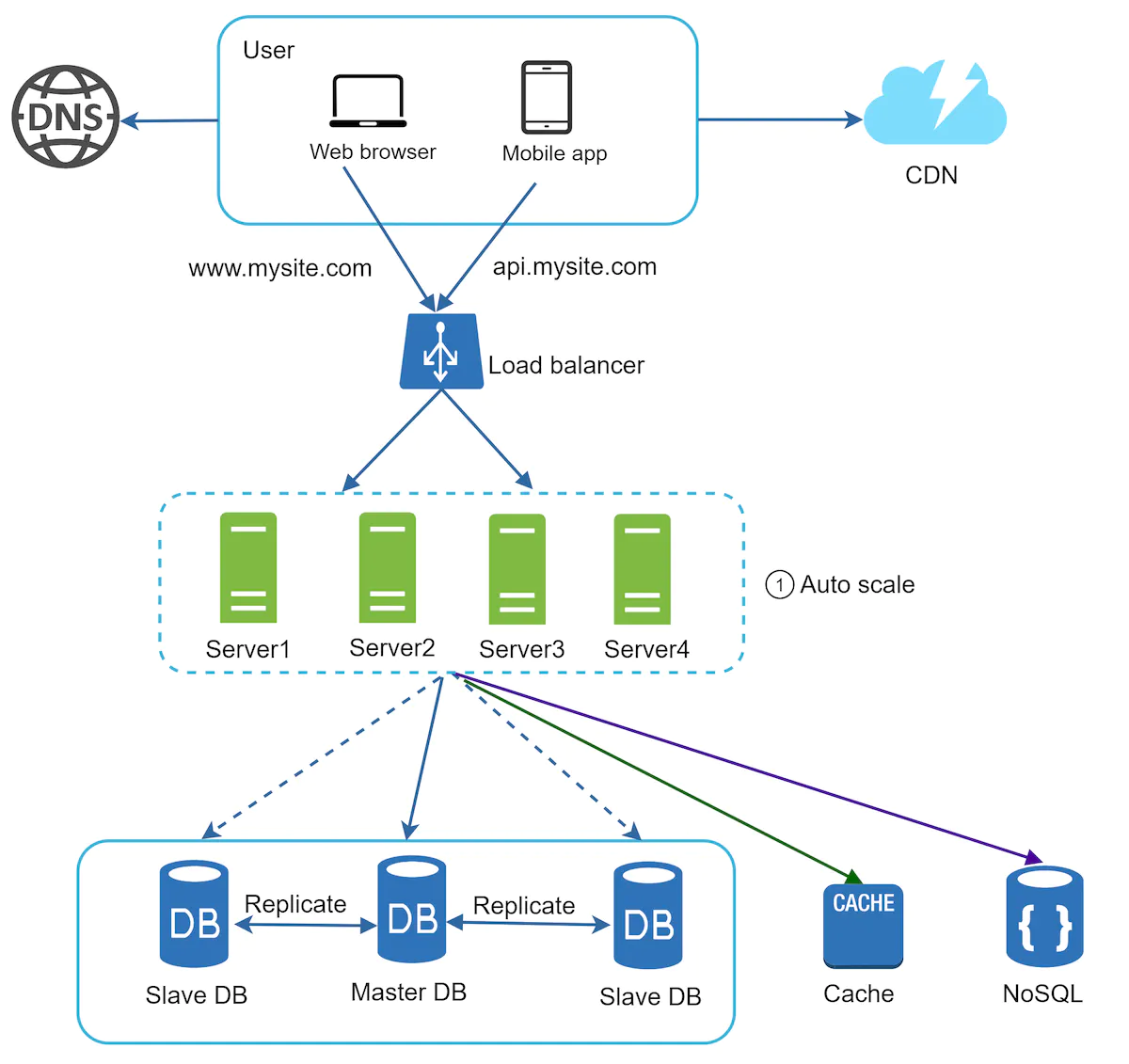
Database
We have two forms of databases
- Relational Databases : These are used to store and keep values in tables and rows. They provide an easy way to join data.
- Non Relational Databases : These are newer and tend to include things like NoSQL
We ideally want to use Non Relational Databases when we’re dealing with applications that require low latency, unstructured or massive amounts of data.
Master/Slave
When we reach a high enough volume, we’d ideally want to migrate over to a master-slave configuration.
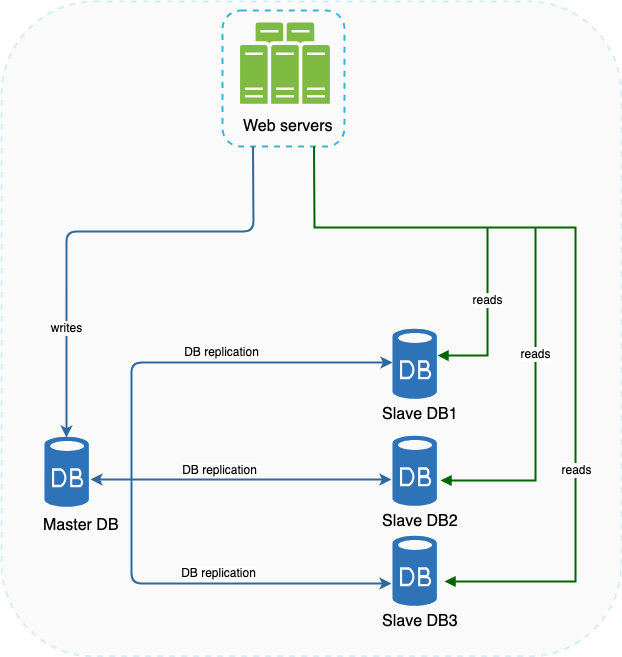
Possible Events
-
Master DB going down : In the event that our master DB goes offline, then a slave database is prompted to temporarily become the master DB
-
Slave DB Unavailable : Master DB takes over the role of a Slave instance temporarily while we await the provisioning of a new Slave DB.
Scaling
When we want to scale our databases, we have two options - Horizontal Scaling or Vertical Scaling. Vertically scaling our database involves increasing its overall capacity while horizontally scaling our database involves increasing the number of instances we have in the network.
Note that horizontally scaling our database will result in a larger amount of issues with data consistency. We might also have to denormalize our data to support the new sharded data in our databases
Cache
When we’re working with data, sometimes, we might want to add a cache. This is an intermediate layer between our database and the server.

Typically, we want to use a cache for data that is read frequently but accessed infrequently. When defining a cache, we need two things
- Eviction Policy : How do we remove items when we’re reaching
- Expiration Policy : How long do we preserve data for?
- Failure Mitigation : A single cache server represents a SPOF. How can we scale out the number of instances while preserving the cache
- Consistency : This involves keeping the data store and the cache in sync.
Applications
CDN
A frequent use of a cache is a CDN, otherwise known as a Content Delivery Network. It is a collection of servers which are ideally located geographically close to your users. This reduces latency for users since the request can be resolved in a much shorter duration of time.
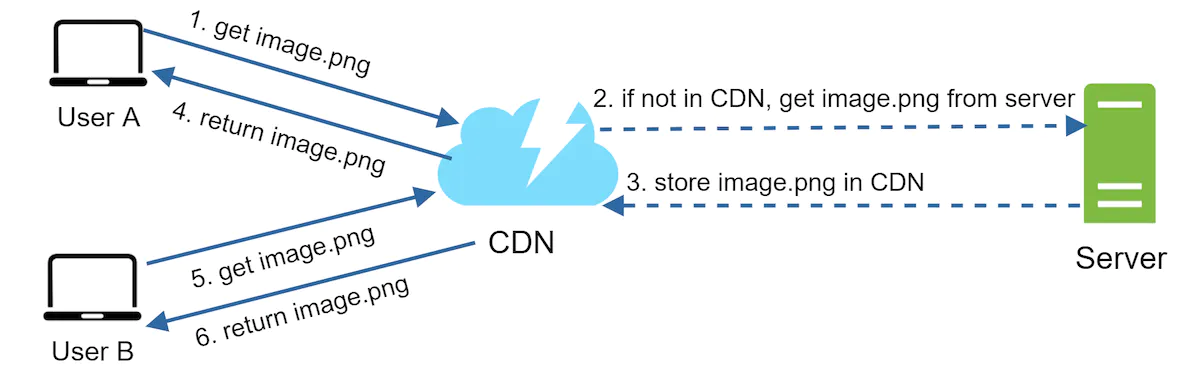
Typically we’d implement the following to ensure our cache works well
- Object Versioning : This helps to ensure we are always serving up the correct version of the model.
- CDN Fallback : In the event that our CDN is unreachable, we need to implement a manual failover to get around it
- Invalidation Lifecycle : We need to make sure that we use APIs provided by CDN vendors to properly ensure validity of objects
Queues
A message queue is a durable component, stored in memory, that supports asynchronous communication. It serves as a buffer and distributes asynchronous requests.

Producers create jobs published as Messages and Consumers consume these jobs.
Decoupling makes the message queue a preferred architecture for building a scalable and reliable application. With the message queue, the producer can post a message to the queue when the consumer is unavailable to process it. The consumer can read messages from the queue even when the producer is unavailable.