Questions
Suggested questions were
- How many people use the product?
- What feature are important?
- How do users connect with the mail server?
- Can emails have attachments?
As an email server, data loss is not acceptable. Therefore, we must have strong reliability and the system should continue to function despite partial system failures.
The estimated load of the server is
- 1 billion users ( 1 x ) assuming that users send 10 emails and recieve 40 emails per day, with an average metadata size of 50kb
- Send Email : request/second to send an email
- Recieve : kb which translates to roughly kb which is equivalent to 730 PB per year
Design
We need to support two main flows
- Email Sending flow
- Email Receiving flow
Email Sending

We utilise a load balance and a message queue to ensure our consumers do not become overwhelmed.
Web servers help to perform basic validation of the email. In the event that the user is sending an email to himself, then the email is never stored in an outgoing queue.
Outgoing workers ( step 5 ) mainly ensure that every message contains all the metadata required to send the email out. They also validate that the email being sent is virus and spam free before shooting it out. If the recipient’s email is not available, then a retry is configured for a later time.
Email Receiving Flow
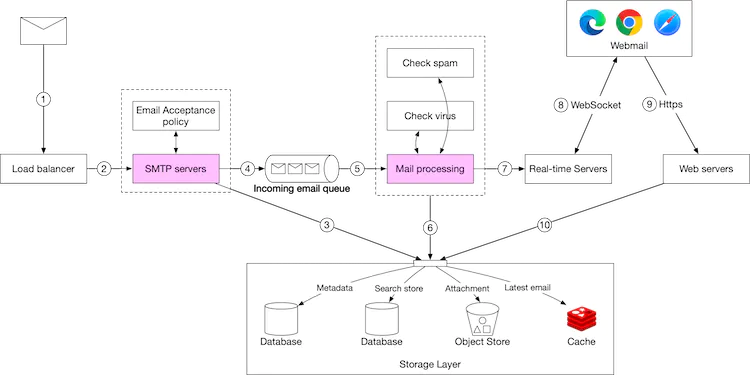
We use a SMTP protocol to receive emails. Once an email is received, we do a few things
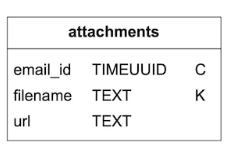
- If attachments are too large, we decouple attachments and put them in the object store
- We utilise a queue to act as a buffer while we process the email. This is an important step because we need to check for spam mails, viruses etc
- We then update the email and store it in the mail storage, cache and upload other attachments to the object data store.
- Lastly, if a user is online, we push the email to his/her device.
Databases
Ideally what we need is a database whereby we can get indexed queries quickly even when the individual email is up to 100kb.
This makes relational databases a bad fit, since they are optimised for small chunks of data entries. Distributed object storage is also not a good fit since we cannot efficiently support indexing of data, marking specific emails as read etc.
In this case, since our workload will be much more write heavy than read heavy, NoSQL databases might be a good solution.
Data Model
We need two things for our databases
- Partition Key : How we distribute data across nodes
- Clustering key: How we sort data within a single partition
We have a few different types of data we need to store
-
Emails By Folder: For user emails, we can partition by user_id and cluster it by the timestamp that it was received at.
-
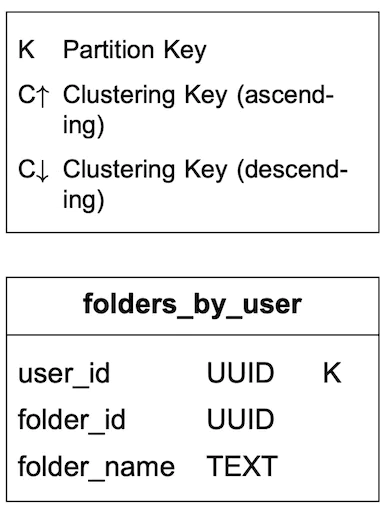
Users Email Folders : For user email folders, we can partition it by user_id ( No real need to sort )
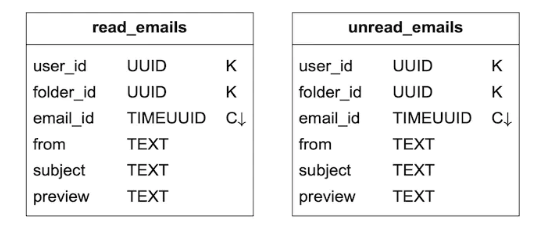
 Note here that we store read and unread emails in separate tables. This is known as denormalisation in NoSQL and helps us to have a much more performant operation.
Note here that we store read and unread emails in separate tables. This is known as denormalisation in NoSQL and helps us to have a much more performant operation.
Search
We can support email search in two main ways
- We integrate it within our database itself with a custom built integration
- We utilise a provider such as Elasticsearch
Search is important since indexing should be near real-time and the result has to be accurate.
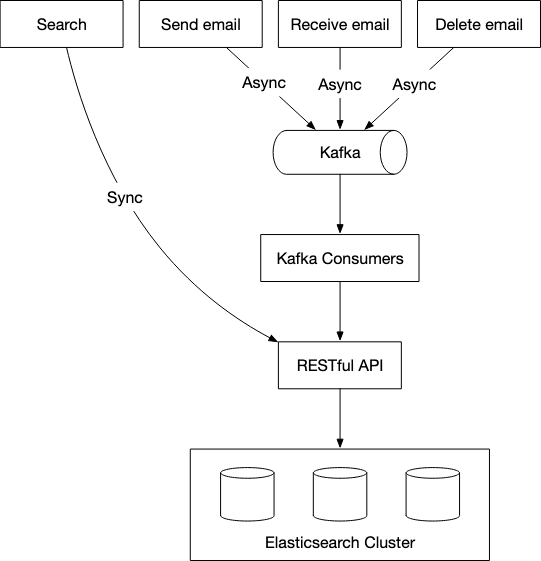
We utilise a Kafka cluster here to act as a buffer between the services that perform reindexing and those that trigger the reindexing.
A general rule of thumb is that for a smaller scale email system, Elasticsearch is a good option as it’s easy to integrate and doesn’t require significant engineering effort. For a larger scale, Elasticsearch might work, but we may need a dedicated team to develop and maintain the email search infrastructure. To support an email system at Gmail or Outlook scale, it might be a good idea to have a native search embedded in the database as opposed to the separate indexing approach.
Scalability
We also use data replicated across multiple data centers. This provides two main benefits
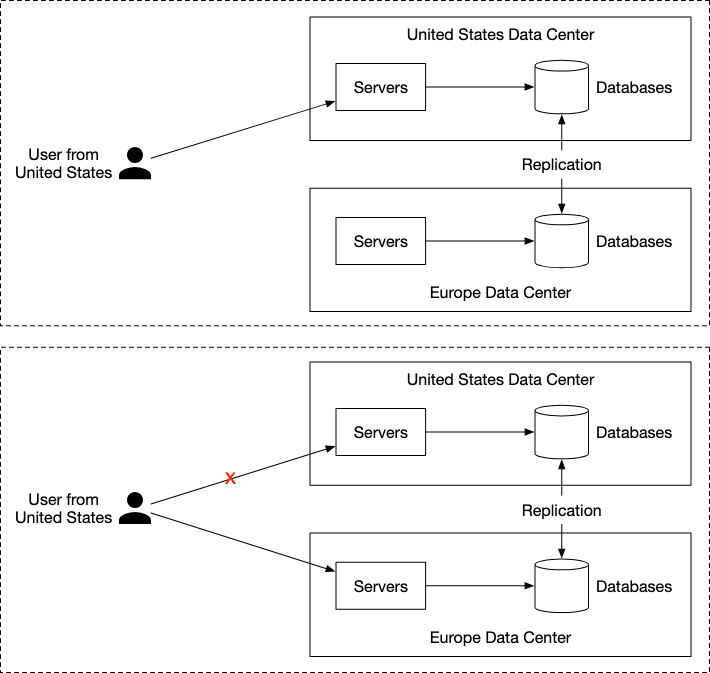
- Users can communicate with servers that are closer to them, allowing for better latency.
- Users data is more secure, since in the event of a data center going down, we have another one as backup.
Concepts
Email Protocols
We have 4 different protocols to send and receive emails.
- SMTP: Sending emails from one mail server to another
- POP: Standard mail protocol to receive and download emails from a remote mail server to a local email client. Once emails are downloaded to your computer or phone, they are deleted from the email server. This means that the email is available only on your computer
- IMAP: IMAP only downloads a message when you click it BUT does not delete the email from the server. This allows you to view the same email on multiple devices
- HTTP: We can use it to access our mailbox for web based emails. Outlook uses HTTP to talk to mobile devices using a protocol called ActiveSync
Metadata
Typically, we can utilise an email header to store information about the email. This allows us to embed information such as the email thread within the header itself.
{
"headers" {
"Message-Id": "<7BA04B2A-430C-4D12-8B57-862103C34501@gmail.com>",
"In-Reply-To": "<CAEWTXuPfN=LzECjDJtgY9Vu03kgFvJnJUSHTt6TW@gmail.com>",
"References": ["<7BA04B2A-430C-4D12-8B57-862103C34501@gmail.com>"]
}
}