A message queue is a process which allows us to route messages from producers to consumers.
Questions
The suggested questions were
- What is the format and average size of messages. Is it text only and is multimedia allowed?
- Can messages be repeatedly consumed?
- Do messages need to be consumed in the same order that they were produced?
- Does data need to be persisted and what is the data retention policy.
- How many producers and consumers are we going to support
- What is the data delivery semantic we need to support - at-most-once, at-least-once and exactly once.
- What is the target throughput and end-to-end latency.
Design
The following design is for a messages queue system that
- has persistent messages.
- Allows for the consumption of messages repeatedly or only once
- Allows for historical data to be truncated
- Provides configurable data delivery semantics - users can decide at most once, at least once and exactly once.
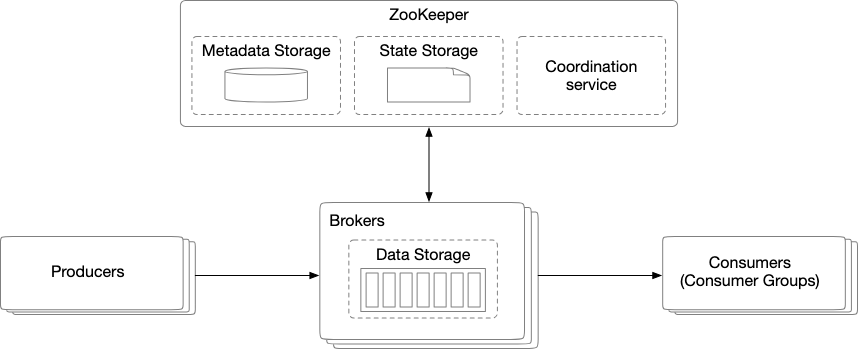
We can see a sample first design for a message queue system. Note here that we have
- Coordination System : This helps to keep a list of which brokers are alive ( to send messages to ) and to designate a active controller. This means that it acts as an intermediary to validate, store, route and deliver the messages to the right destination.
- Data storage Which allows us to persist the messages in data storage in partitions.
- State Storage : This stores a mapping between partitions and consumers as well as the last consumed offsets of consumer groups for each partition. Normally, we want to have a KV store to store consumer state data using a KV system like Zookeeper.

We can also further simplify our design by using software like Zookeeper which provides the configuration service, synchronization and naming registry out of the box. We can therefore redesign our setup as such
Storage
When choosing a mechanism for storage, we have three main options
- A Relational Database : We create a table topic and write messages to the table as rows
- NoSQL Database : We create a collection as a topic and write messages as documents.
- Use a Write Ahead Log ( WAL ): This is a text file which provides an append-only log.
We avoid the use of the databases because a message queue is write and read heavy. Therefore at a high scale, we will find issues scaling up our system.
A WAL is a more appropriate choice because of the following reasons
-
We can batch updates to the WAL
-
Sequential access is pretty fast with rotational disks. Modern disk drives can comfortably achieve several hundred MB/s of read and write speed which is more than sufficient for our messages which are at most kilobytes.
-
Easy partition with segmented files
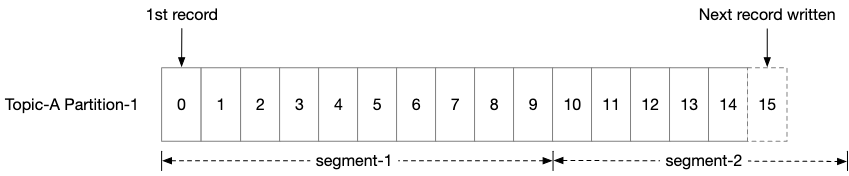
This gives us an easy way to persist data as well as to allow for messages to be consumed in the order that they are sent.
Concepts
A message queue is a simple piece of software which has the rough structure of

We have producers that produce messages ( these could indicate some sort of event or some command to be executed downstream ) and consumers that are subscribed to the stream of messages.
Both producer and consumer are clients in the client/server model, while the message queue is the server. The clients and servers communicate over the network. By using a message queue, we can decouple our producers from our consumers - allowing each to scale and operate independently.
Messaging models
We have two main messaging models
- Point to Point - Single consumer per message
- Publish-Subscribe - Multiple consumers per message
Point to Point
This is a traditional message queue. Once a consumer acknowledges that a message is consumed, it is removed from the queue. There is no data retention in the point-to-point model.

Publish-Subscribe
In a publish-subscribe architecture, we group messages by a unique identifier we call a Topic. This is a name that is unique across the entire message queue system.

Consumers subscribe to specific topics and consume the upstream data from them. This allows for specialised workers per topic.
Distributed System
Topic Sharding
After some time, our message queue will not be able to store all of its data in a single volume - it will become too hard for a single. Therefore we will shared our topic message using partitions.
- A server that holds partitions is called a broker
- A subset of the topic’s message is called a partition
- A broker server can hold multiple partitions - the relationship is not 1:1
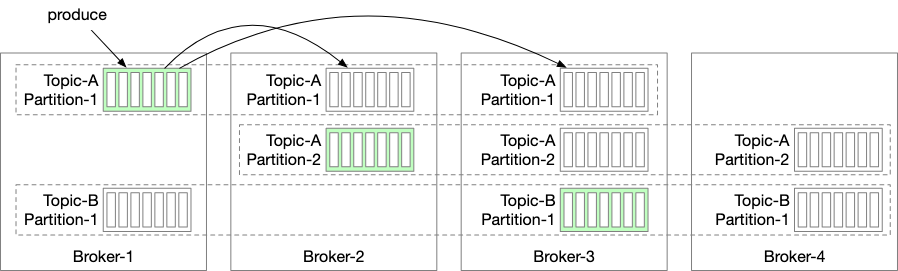
We can see an example here of sharding where data is replicated across 4 different brokers. By doing so, we are able to ensure high availability of data since there is always a broker which has a copy of the data.
In-Sync Replicas
In-Sync replicas are replicas which are at most n messages off from a leader.
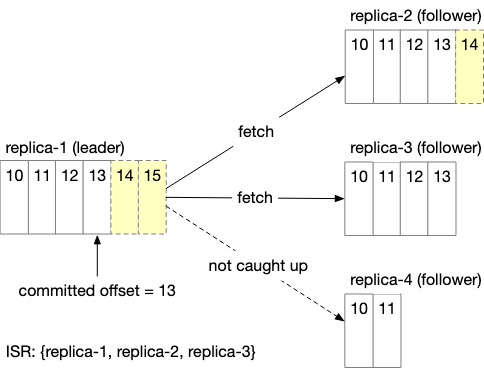
By ensuring that we only populate replicas that are in-sync with our leader, we prevent a single slow replica from causing the whole partition to become slow or unavailable.
We can do ISR by either going for
- Ack=All : All replicas must be in sync before we proceed to send acknowledgement of message received.
- Ack = 1 : We just need a single replica - in this case the leader to confirm message has been recieved.
- Ack = 0 : We don’t need any confirmation, producer keeps sending messages to the leader without waiting for acknowledgement and never retries. This is good for use cases when data volume is high and occasional data loss is acceptable
We can further improve on this by ensuring that our replicas are spread out across different geographical data centres and servers. This way, when a single replica crashes, we don’t lose all of the data. We can also improve on it by allocating more replicas than specified in a config file when provisioning new replicas. We only decomission replicas when old ones come online.
Consumer Groups
Consumers will be split into what are known as consumer groups - these are a set of consumers that are working together to consume messages from topics.

Typically, if we have a consumer group, then we try to make sure that only one consumer reads from each partition. This helps to ensure that the consumption order of messages in the same partition is preserved.
We do so by ensuring that only one consumer within a consumer group is allowed to read from a partition.
Batching
Often times, we’d like to find ways to speed up our system. That’s where batching comes in. We can perform batching at three different levels
WAL
Our write ahead log benefits tremendously from batching multiple updates together.
- It allows the operating system to group messages together in a single network request and amortizes the cost of expensive network round trips.
- The broker writes messages to the append logs in large chunks, which leads to larger blocks of sequential writes and larger contiguous blocks of disk cache, maintained by the operating system. Both lead to much greater sequential disk access throughput.
Producers
We can also perform batching on the producer side
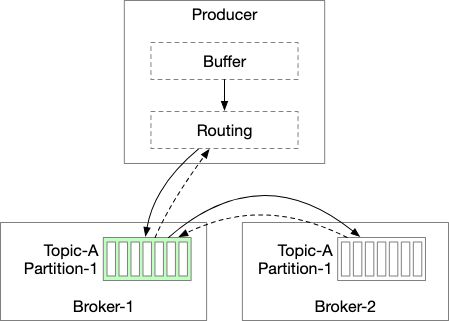
Note here that we directly provision the routing and buffer layer onto the producer to reduce the network hops and allow for producers to have their own logic to determine the partitions. By sending out larger batches in a single request, we can increase throughput.
Consumers
Reading Messages
Consumers are able to read from a specific point in the message queue by taking advantage of the WAL structure.
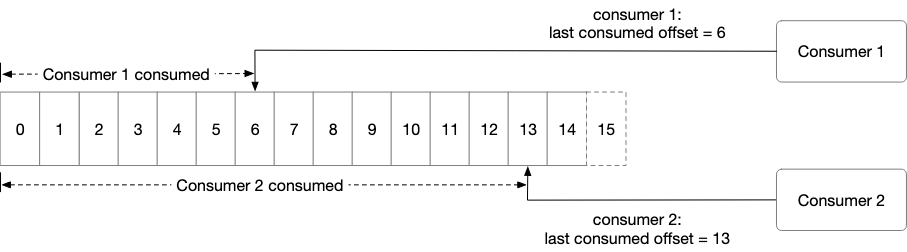
This allows for messages to be consumed in the order that they are sent. There are two main ways for consumers to consume data
- Push : Message queues send message out as soon as they arrive to consumers.
- Pull: Message queues retain message and allow consumers to pull the data when they are ready
Typically, the pull method is more suitable for batch processing. To prevent a consumer from repeatedly pulling data when there are no messages, typically we combine it with a long polling mode that allows the pulls to wait a specific amount of time before trying to acquire new messages.
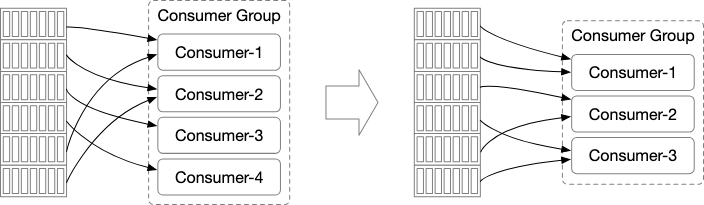
Rebalancing
Brokers will routinely rebalance the distribution of consumers to allow for a more balanced consumption model.
In the event that a consumer goes down, the brokers will try to re allocate consumers. The same happens when we have more consumers.
Message Filtering
We can also implement message filtering by having the broker decide which messages to send to each consumer. Consumers can subscribe to specific tags and work from there.

Delayed Messages
We can also support delayed message by using temporary storage. Most current implementations do not support delayed messages with arbitrary time precision. They only support specific levels.
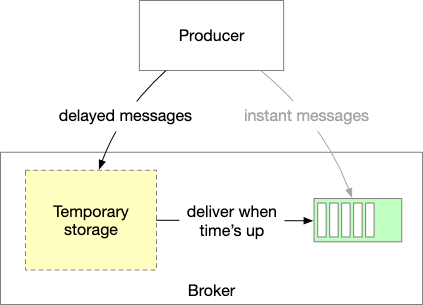
In this case, Message delay levels are 1s, 5s, 10s, 30s, 1m, 2m, 3m, 4m, 6m, 8m, 9m, 10m, 20m, 30m, 1h, and 2h.
Data Delivery Semantics
There are three main possible data delivery semantics in a messaging queue system. These affect how the consumer interacts with the messaging queue.
At Most Once
Messages will be delivered not more than once.
- Producer will send message without acknowledgement ( ack = 0)
- Consumer will acknowledge offset before finishing the task - hence if it crashes midway then the message will not be re-consumed

At least Once
Message will be delivered at least once
- Producer will wait for acknowledgement ( ack = 1 or ack = all ) and continually retry until acknowledgement has been sent.
- Consumer will fetch and commit the offset only after the data has been processed. This might however, result in duplicate messages if another consumer reads the message before the first has fetched and committed the offset.

Exactly Once
This is very difficult to implement.

Use cases: Financial-related use cases (payment, trading, accounting, etc.). Exactly once is especially important when duplication is not acceptable and the downstream service or third party doesn’t support idempotency.