A notification system is used to deliver messages to users on a specific platform. Notifications can be late, but they cannot be lost.
Questions
I generated the following questions
- How many notifications do we send per day?
- How are the notifications categorised? Are there different notifications with different priority levels?
- Do we need to log what notifications we send? If so, how granular must the logging be
- How long do we need to store notifications for?
- How do we get the list of notifications to be sent?
Here were some other questions recommended
- What type of platforms do we need to send these notifications on?
- Is it a real-time system?
- What triggers the notification?
- Can users-opt out?
- What are the supported platforms to send notifications for.
Background Knowledge
When we want to send notifications, we need to use a device-specific platform.
-
Apple : We need to use the Apple Push Notification Service (APNS) which is a cloud service that allows approved third-party apps installed on Apple devices to send push notifications.
-
Android : We can use the Firebase Cloud Messaging platform to send notifications. However, in countries like China, we might need to use an alternative platform like JPush or PushY.
-
SMS : Twilio
-
Email : We can use Sendgrid or other providers
Architecture
Initial Draft
We can utilise a single notification service which exposes an endpoint which other services can call in order to send notifications to a user.
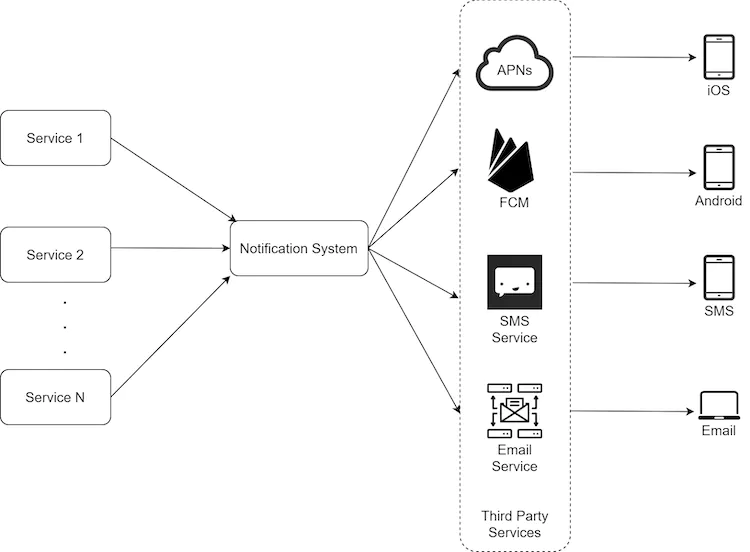
Data Storage
User data can be stored in a table that looks like
User Table
- user_id
- email
- country_code
- phone_number
- created_at
Device Table
- device_id
- user_id
- device_token # This is a unique identifier which we can use to identify a specific device
- last_logged_in_at # This is a timestamp
Note that the Users -> Device mapping is a one-to-many relationship whereby one user can have many unique devices.
Problems
One of the main problems here is that we are utilising a single service to handle everything - from the parsing of the notification payload, to analytics and even the retry mechanism in the event of a failed notification.
As a result, it is hard to scale and is a single point of failure.
Updated Architecture
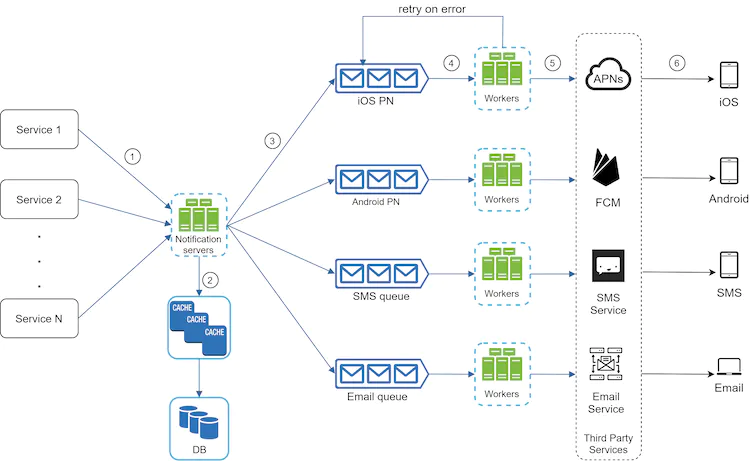
Some new updates that make this better are
- Automatic retry handled by a queue and a worker
- Separate message queues for each type of notification - This allows for parallel processing of information and limits the ability of a single service going down to affect the others(Eg. if APNS is down then we can still send using FCM, SMS, Email )
- The use of a cache and a db to ensure that any data needed to fetch the data can be fetched easily and cached for future work
- The use of a few different servers with LB to effectively distribute load when query volume is high
New Considerations
-
Data Loss : We prevent data loss by introducing a database for each notification worker cluster to persist jobs, and to subsequently handle retries.
-
Analytics : Now that we have a much more complex system, we need to introduce new logs to track
-
De-duplication : In a distributed system, we might have notifications sent twice by accident. Therefore, we must introduce a de-duping mechanism to stop this
-
Notification Templates : We can create notification templates to maintain a consistent format and save time. This can be persisted in the DB.
-
Notification Settings: Users need to be able to indicate their preference for receiving notifications and if so, what type of notifications. We can store it in a database table
-
Rate Limiting : We can rate limit our processes from sending too many notifications at one time. This can be implemented using a simple token bucket - when this happens, simply schedule a retry down the line.