A search autocomplete system helps users to get suggestions for their query as they type it. Generally, we get a response from our search autocomplate system with every character that the user types, hence latency must be low.
Facebook’s autocomplete system fires a response in about 100ms.
Questions
I came up with the following questions
- How many queries do we get everyday
- How many users do we need to support?
- How should we rank queries?
- What latency should the system perform under?
- What type of queries are expected?
These were some additional suggested questions
- How many autocomplete results to return
- Is matching supported only at the start or in the middle
- Are search queries in english?
- Do we allow capitalisation and special characters
- Are all queries going to be in english?
Estimation Figures
- We have about 10 million daily active users ( DAU )
- Users perform about 10 searches per day. Assuming that each query contains about 20 characters
- That’s about 20 bytes of data per query string ( Assuming that we have a query containing 4 words, and each word containing 5 characters on average )
- We also have 20 requests being sent to the backend for autocomplete suggestions for each search query
- This translates to about 10,000,000 * 10 * 20 ~ 2 billion queries per day. This works out to around (2 billion / 24/3600) = 24,000 queries per second. We can then estimate a peak QPS to be about 48,000.
- If we assume that ~ 20% of the daily queries are new queries, and we get about 10,000,000 * 10 = 100,000,000 queries a day. This means that we have around 20,000,000 new queries a day. This works out to around 400,000,000 bytes ~ 0.4 GB of new data added to storage daily
Design
Our system has two main components - a data gathering service and a query service. Our data gathering service aggregates data on queries in the form of a frequency table while our query service returns a list of the top k suggestions based on a user’s query.
Data Gathering
Conceptual
We can utilise a Trie in order to store data on our queries. Tries offer quick lookup based on a prefix in O(p) time, where is the length of the prefix.
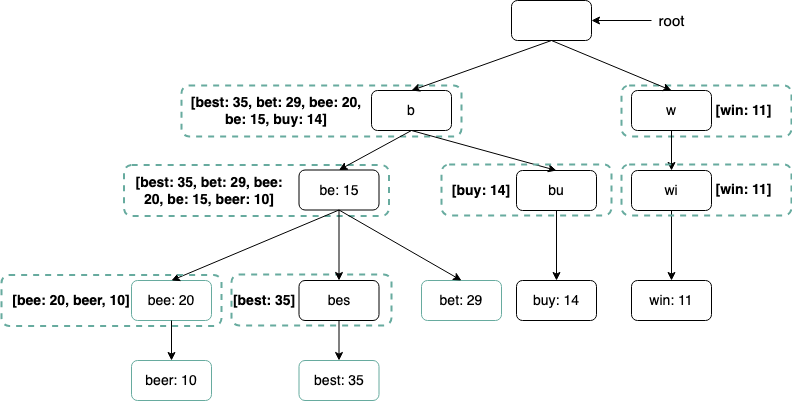
We can cache the top k most relevant results based on historical search frequency in our trie to allow for quick lookup in roughly time. This is because
- We can limit the length of the prefix to a constant size ( Eg. we have a max prefix size of 9 )
- We can cache the top most frequent results in the trie node itself, therefore lookup for top k queries becomes a operation
Architecture
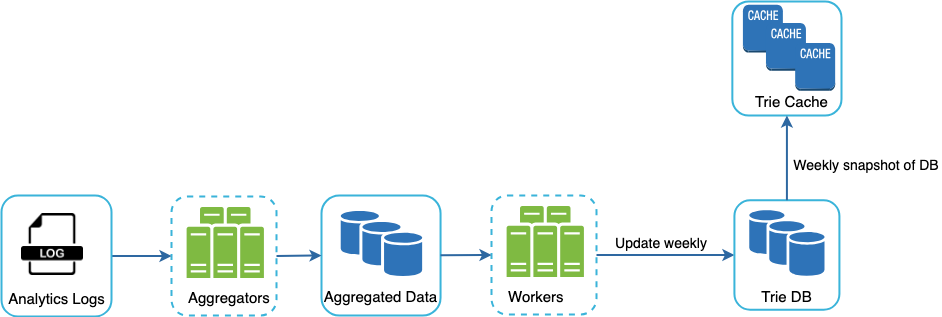
The important thing here to note is that the architecture and update duration will vary based on the requirement. If you’re twitter and you need a real-time update based on consumer trends, then you can’t update your queries weekly. If you’re google, then maybe that works.
We utilise
- Analytics Logs : These are append-only and are not indexed. We simply store a query and the timestamp for when it was made
- Aggregation : We aggregate queries based on the week they occurred. The following table is an example
| query | time | frequency |
|---|---|---|
| tree | 2019-10-01 | 12000 |
| tree | 2019-10-08 | 15000 |
| tree | 2019-10-15 | 9000 |
| toy | 2019-10-01 | 8500 |
| toy | 2019-10-08 | 6256 |
| toy | 2019-10-15 | 8866 |
-
Trie : We utilise a combination of a Trie Cache and a Trie DB to store the data. Most web servers will read from our Trie Cache with data persisted in our Trie DB for the most part. Since our Trie is rebuilt weekly, then we can periodically take a snapshot of it, serialise it and then store the data in the database.
We can also store our Trie in a hash table as seen below
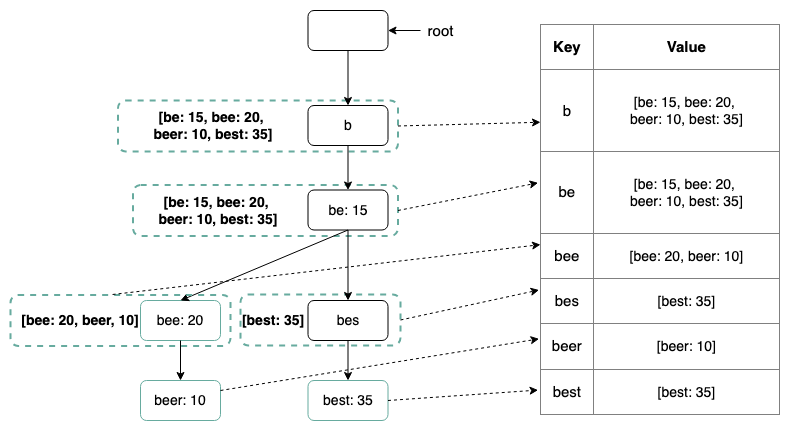
Query Service
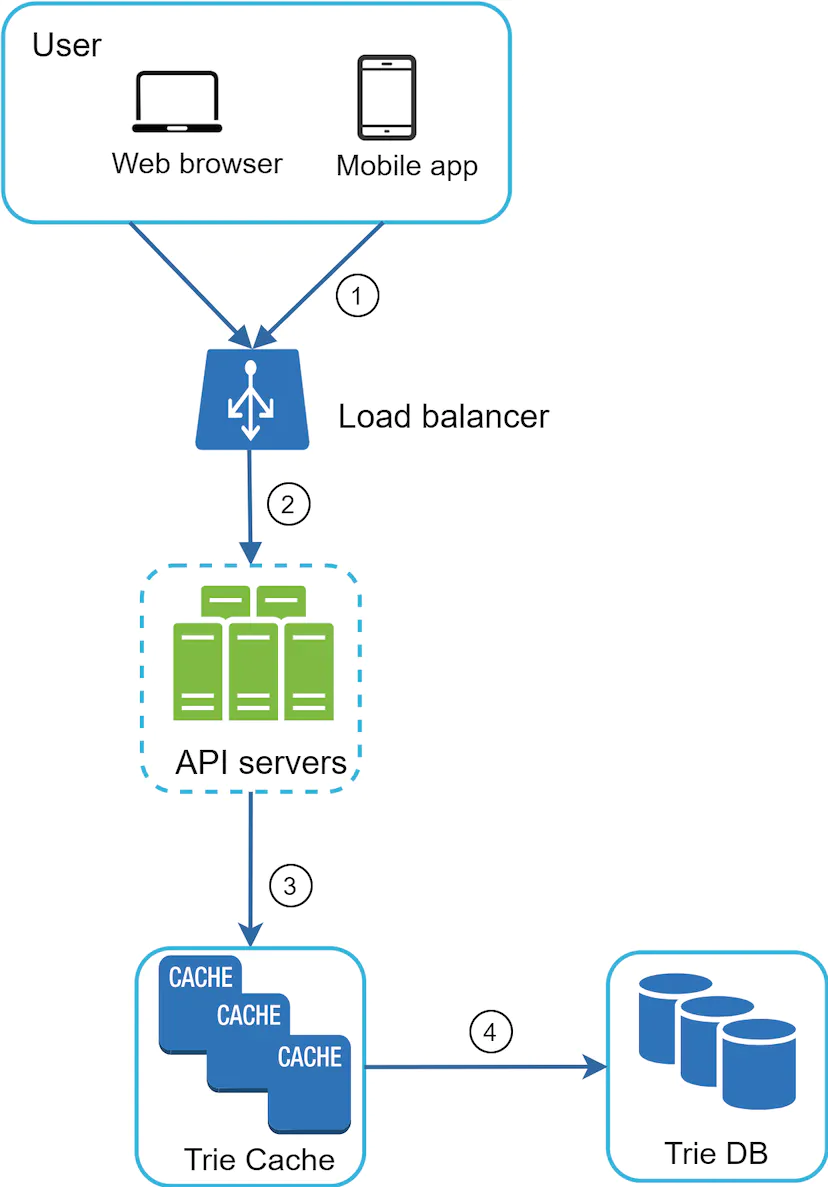
We can utilise a combination of a Trie Cache and a Trie DB to serve up queries. This means that in case the data is not in Trie Cache, we replenish data back to the cache. This way, all subsequent requests for the same prefix are returned from the cache. A cache miss can happen when a cache server is out of memory or offline.
Some additional optimisations that we can perform are
- AJAX Requests AJAX requests which are quicker and do not require updating the entire page.
- Browser Cache : Engines like google utilise browser cache by setting a header of
cache-control: private,max-age=3600.
Notes
Updating the Trie
There are two main ways to update our Trie
- Complete Replacement : We update it weekly and replace the entire old trie in our db with the new one. ( We can also backup old tries in a document store for easy rollbacks in the event of a failover or issues )
- Individual Nodes : If we have a small trie, we can update a single node and then back propagate up the new updates to its ancestors up to the root.
Content Moderation
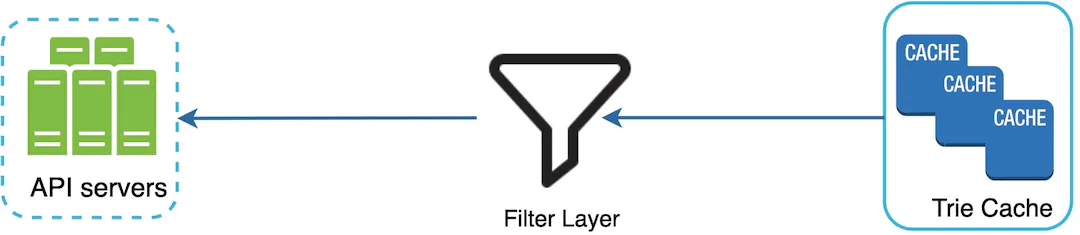
We can utilise a filter layer to remove results based on filter rules. These violent, hateful, sexually explicit or dangerous autocomplete suggestions can then be removed from the main Trie down the line when we perform our updates.
Sharded Storage
Eventually, we will not be able to store the queries on a single machine. This might come as the result of having too many queries to process. Therefore, we need to use a shard map manager which will maintain a lookup database for identifying where rows should be stored.
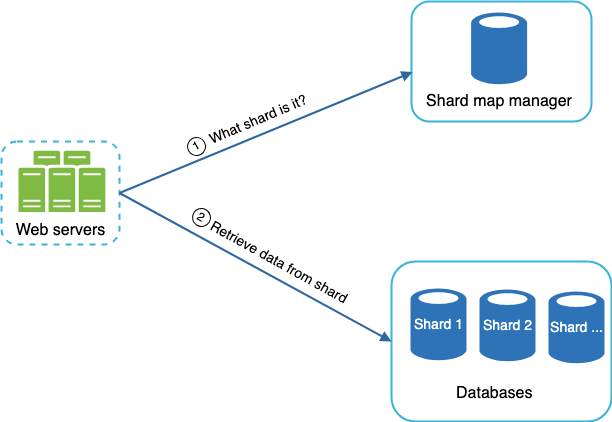
We can perform sharing by either
- Shard by Character : This is easy to implement but might result in an imbalanced sharing mechanism
- Shard by historical data : We look at historical query distributions and then maintain shards based on query sizes. For example, if there are a similar number of historical queries for ‘s’ and for ‘u’, ‘v’, ‘w’, ‘x’, ‘y’ and ‘z’ combined, we can maintain two shards: one for ‘s’ and one for ‘u’ to ‘z’.
Additional Notes
- We can support multiple languages by storing Unicode characters in Trie nodes
- We can build different tries for different countries and store these tries in CDNs