Questions
Here are some questions I came up with
- How many pages to crawl per hour / month?
- How long should we be storing data for?
- Will we be crawling any protected pages?
- How do we determine what to crawl?
Here are some recommended questions
- What is the main purpose of the search index crawler
- How many web pages does the crawler collect per month?
- What content types are included?
- How should we handle duplicate pages?
Estimation
Figures given ~ Need to store for around 5 years and the crawler will hit around 1 billion pages per month
Estimates
- QPS : 1 billion / 12 / 30/ 24 / 3600 = ~ 400 pages/second
- Peak QPS : ~ 800 pages/ second
- Assume that each page is ~ 500kb, this means that per month we need about 500 TB of space per month.
- Assume that data is stored for 5 years, this means that we need ~ 30 PB of storage to store five years of content
Architecture
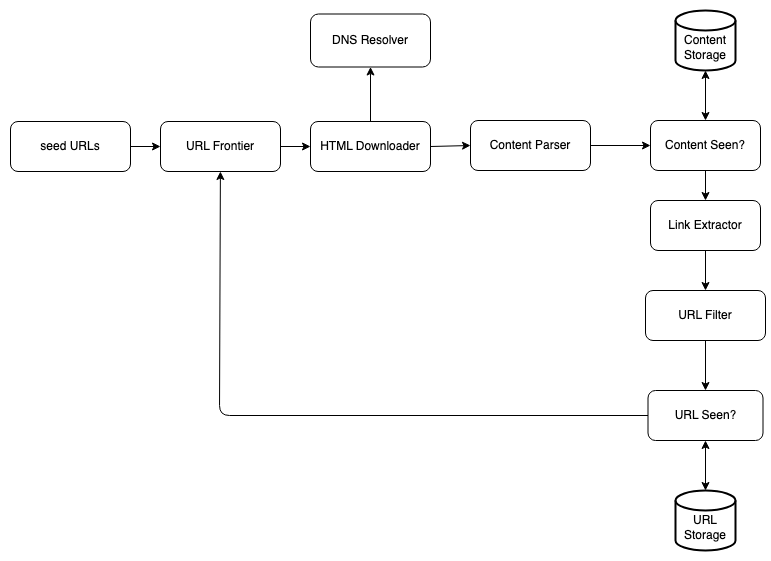
- Seed URL : Initial starting point of URLs
- URL Frontier : List of URLs to be crawled ( page content has not been downloaded yet )
- DNS Resolver : Given a URL, we get the IP Addr
- HTML Downloader : Download the HTML content of the page given a url
- Content Parser : Parse HTML content and determine if page has been crawled correctly or not
- Content Seen : Compute a MD5 Hash of the page content and determine if we’ve seen it before - possible to use a hash table or a bloom filter for this
- Content Storage : We use a combination of disc storage and RAM in order to store our content. Recently accessed/popular sites might be kept in storage while others are not.
- Link Extractor : Extract out all of the different links in the extracted HTML and convert to an absolute url link
- URL Filter : Remove any undesirable links - eg. those that are blacklisted or belong to sites which should not be crawled
- URL Seen : New Urls that were extracted in the link extractor are then passed to a single component whose’s sole purpose is to identify whether or not to add it to the URL Frontier or not
Considerations
Ideally, we want to make sure that we crawl sites in a friendly manner. A good way to do so is to combine a BFS approach with some additional optimisations.

-
Politeness : We do not want to overwhelm servers with our requests. As a result, we only allow worker threads to crawl a specific subset of assigned URLs. This is done by maintaining a map of url <> Queue. URLs are added to a specific queue and worker threads consume new URLs that are added to that queue. In short, our queues to worker threads share a one-to-many relationship.
-
Prioritisation : We need to make sure that we crawl websites according to their relevance. Therefore we utilise a prioritiser service which is able to decide on the prioritisation of a url. It then adds it to a specific queue that corresponds to its assigned priority.
-
Memory Speed : We maintain a buffer in memory to allow for us to read/write quickly to the disc space.
-
Timeout : We implement a timeout in order to make sure that we don’t spend too much time waiting on a host. If a host does not respond within a predefined time, we will move on to another URL
-
Consistent Hashing : We can add/remove server processes using consistent hashing. This will help us to prevent system errors in the event that specific worker processes go down.
-
Server-Side Rendering : We can utilise a javascript process to render pages that are using scripts to generate links/content on the fly