A key value store is a non relational database that allows us to store unique identifiers that are mapped to their respective values
Considerations
When designing a key value store, here are some good questions to ask
- How large are the individual key-value size pairs
- What should we prioritise for this system - Availability or Consistency?
- How much data are we expected to support?
Architecture
We progressively increase the difficulty of our KV store design
Single Server
When developing a single server key value store, we can store data in memory. In the event that our data becomes too large to store in a single server, we can either compress our data or store only frequently used data in memory and keep the rest on disk
Distributed Server
Data Partition
In order to achieve high availability and reliability, data must be replicated asynchronously over N servers. We choose a initial server using Consistent Hashing and then proceed clockwise and choose the next servers to store data copies too.
In the event that we are using [virtual nodes](Consistent Hashing#Using Virtual Nodes) then we’ll want to make sure that we choose enough node so that we replicate it to at least N servers.
We can then guarantee the consistency of our data by using Quorum Consensus.
Ensuring Node Avaliability
We use a Gossip Protocol to keep track of nodes which are present within our current network. We can deal with node failures in 2 main ways
-
Sloppy Quorum : This involves simply choosing the first healthy servers for writes and the first healthy servers for reads on the hash ring. Offline servers are ignored in this procedure call.
-
Hinted Handoff: When downed servers finally come online, changes will be pushed back to achieve data consistency. This is done by using a Merkle tree to perform Inconsistency Detection
Coordinator and Nodes
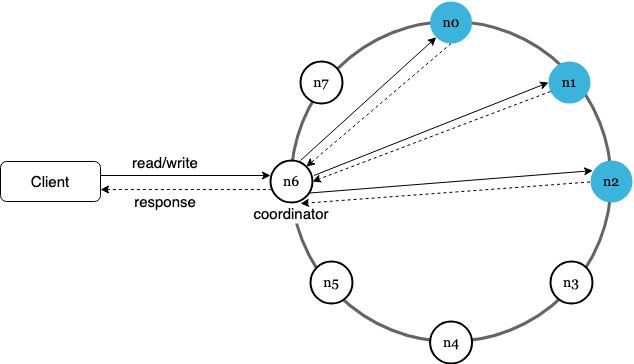
- Clients communicate using an API of
get(key)andput(key,value) - Nodes are allocated values based on consistent hashing of keys
- Adding and removing nodes is easy to support
When each node is being queried, we can utilise a combination of the following three elements to support fast queries
-
Memory Cache : Frequently queried data is stored in a memory cache for easy access
-
Bloom Filter: If a key does not exist in our memory cache, we can use a bloom filter to quickly determine whether a key is absent from our dataset
-
SSTable : In the event that the key might be present in our dataset, we then query our SSTable to find the value of the dataset.
Concepts
CAP
CAP stands for Consistency, Availability and Partition Tolerance. A distributed system can only have two of these properties.
- Consistency: consistency means all clients see the same data at the same time no matter which node they connect to.
- Availability: availability means any client which requests data gets a response even if some of the nodes are down.
- Partition Tolerance: a partition indicates a communication break between two nodes. Partition tolerance means the system continues to operate despite network partitions.
In real, life, since a distributed system must tolerate network partitions due to unavoidable network failures, we have only two possible types of systems
-
Consistent and Partition Tolerance (CP) : All nodes must have the same values. If a node goes down, we block reads until it comes back up.
-
Available and Partition Tolerance (AP) : All nodes will eventually have the same value. If a node goes down, we just continue accepting reads and sync the node when it comes back up
Quorum Consensus
Simply put, we define the following variables
N : The Number of replicas W : The size of the write quorum. For a write operation to be considered as successful, write operation must be acknowledged from W replicas. R : The size of the read quorum. For a read operation to be considered as successful, read operation must wait for responses from at least R replicas
- Note that the size of the quorum is separate from the amount of nodes we have replicated the data to.
- The configuration of and is a tradeoff between latency and consistency. We can toggle the values around to get the following results
If R = 1 and W = N, the system is optimized for a fast read.
If W = 1 and R = N, the system is optimized for fast write.
If W + R > N, strong consistency is guaranteed (Usually N = 3, W = R = 2).
If W + R <= N, strong consistency is not guaranteed.
Consistency
There are a few different consistency models
- Strong consistency : Client never sees out-of-data data
- Eventual consistency : Given enough time, all updates are propagated and all replicas are consistent. ( A form of weak consistency )
- Weak Consistency : Client might see out of data data
We can force strong consistency by making a replica reject new reads/writes until every other replica has agreed on a current write. This is at-odds with current highly available systems.
Versioning
We can use versioning as a way to solve inconsistency among replicas - this means that each data modification is treated as a new immutable version of data. This is normally implemented using Vector Clocks.
Gossip Protocol
Gossip Protocols in a distributed system work as follows
- Each node maintains a membership list of existing nodes in the system
- Each node periodically increments its heartbeat counters
- Each node periodically sends heartbeats to a set of random nodes to update its hearbeat. This in turn propagates to another set of nodes
- Once nodes receive heartbeats, membership list is updated to the latest info
In the event that a heartbeat has not increased for more than a predefined period, the member is considered as offline.
Inconsistency Detection
We use a merkle tree to perform inconsistency detection.
A merkle tree is a tree in which every non-leaf node has a hash that is derived from the hash of the labels of its child nodes. This allows for efficient and secure verification of the contents of its contents.
The procedure is simply
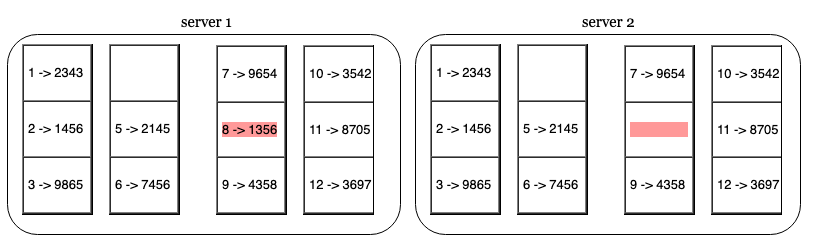
- Divide key space into buckets and hash each key in the bucket using a hash function.
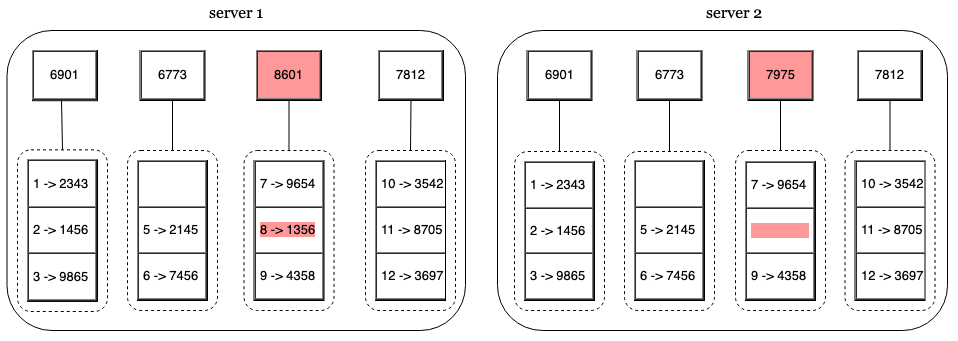
- Next, create a single hash node per bucket using the hashes of the elements within the bucket
- Build the tree upwards by calculating a hash of the children’s own hashes
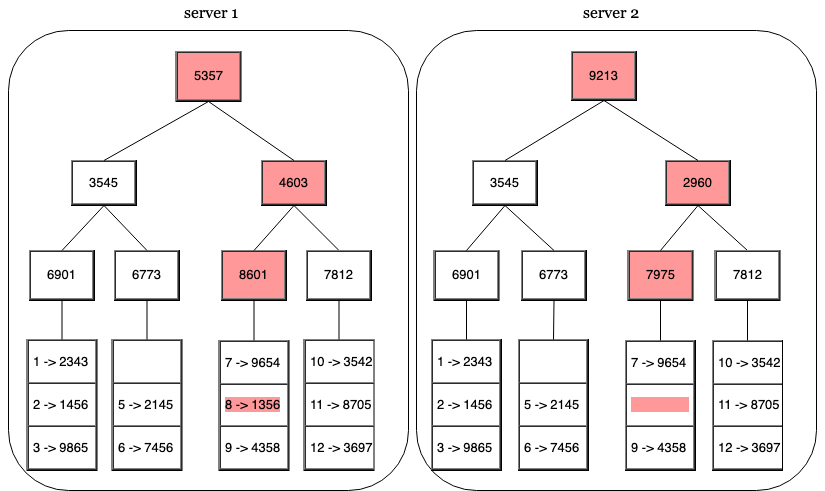
We can identify differences in the data contained within two nodes using merkle trees by comparing the root hashes. If a hash disagrees, we then recursively step through the children until we find the common points.