Questions
I came up with the questions of
- What radius to support
- Does the service need to operate in real time?
- How many DAU do we have?
- Are users location only updated when they open the app?
these were some additional suggested questions
- When should we stop tracking users location?
Design
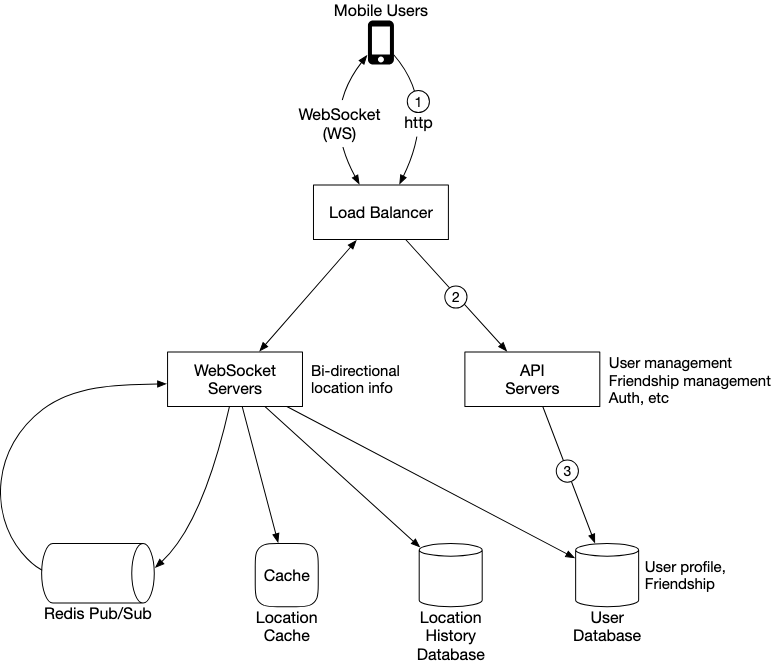
On a high level, we have the following design. Note that we
- Assume that if a user is inactive for more than 10 minutes, he is no longer using the service
- Each user has ~400 friends, of which 10% are going to be active at any given time
- Have around 100 DAU million users of which 10% are concurrent.
- location refresh interval is every 30 seconds
We also need to support a few different features
- See nearby friends on mobile app - Each entry in the friend list has a distance and a timestamp indicating when the distance was last updated
- Nearby friend lists need to be updated every few seconds
Redis Pub Sub
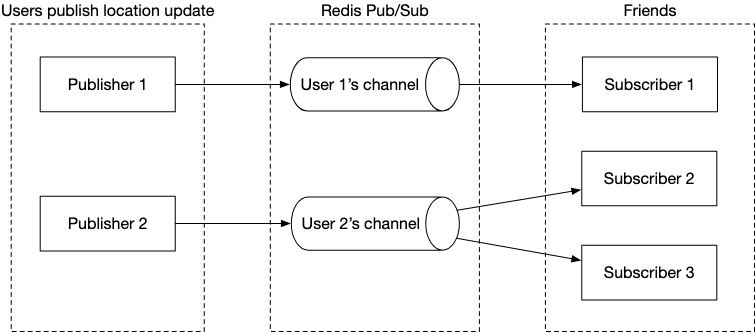
We utilise a Redis Pub sub to update individual clients about the position of new friends. Whenever a user’s location is updated using the websocket client, this triggers a update to the channel and the subsequent subscribers which are subscribed to the chart.
Here are some general points to keep in mind
-
Pub Sub : The Pub Sub model ensures that users are always updated about the location of their friends. Whenever we have a update for a specific user’s location, the model ensures that the relevant websocket server is updated in real time.
We can then simply update and remove friends that fall out of a specific radius. On the frontend, we can assume that if we haven’t had updates for a specific friend by a certain cutoff, we can filter it out of the list and mark the user as inactive
-
Cost : It is relatively cheap to maintain millions of pub-sub channels in redis. Channels in Redis pub/sub are very cheap to create. A modern Redis server with GBs of memory could hold millions of channels.
-
Scaling : There are two main considerations when looking at our redis server. This is storage and CPU. CPU will be the main bottle neck here - assuming that each server can handle about 100,000 updates per second, we need about 140 redis servers.
- Storage wise : Assuming that it takes us 20 bytes to store a pointer to a subscriber’s channel, we need 100 million * 100 * 20 bytes ~ 200 GB
- CPU : Assuming that we have around 10 million concurrent users, with about 100 friends that will be active at any given time, with a single user sending an update every 30s, we have approximately 10,000,000 * 100 /30 ~ 334k updates per second. This means that we need to send approximately 334k * 40 = 14 million updates per second
-
Distributed : We can utilise a simple service discovery package such as etcd or Apache Zookeeper to keep track of all our services. We can then utilise consistent hashing as a simple way to ensure we know exactly which user Ids are mapped to which redis cluster
Caches
We utilise a location cache to store information on our user’s location. Since we only care about the current location of a user, therefore, we only need to store one location per user. We can utilise the TTL as a way to automatically pure users from the cache that are no longe ractive.
The location cache is essential for quickly retrieving the latest location information for any user without having to query the location history database, which could be slower and more resource-intensive.
Some potential uses could be
- When we initialise the app and we need to grab a list of all active friends ( Since only users who have updated their location in the last 10 minutes will be in the cache )
- Failover - in the event that the redis-pub sub goes down, we can implement a fail-over using the the location cache
Our location cache will store information on users with userId mapped to a tuple of (lat,long,timestamp).
Database
We also want to store user’s historical location data. This is a write-heavy workload and will not be able to fit into a single instance. As a result, we need to shard the data. For this, we can utilise a distributed database such as Cassandra.
However, since the scale of our app is quite significant, we cannot utilise the database directly.
A data model for our location history is userId,lat,long,timestamp.
Websockets
We utilise a stateful websocket client so that any new updates are propagated immediately to the user’s client. This client can also handle other pieces of functionality such as
- Adding/Removing friends : In such a case, we want to update the pub/sub subscriptions that our user’s webclient has.
Other Features
Random person
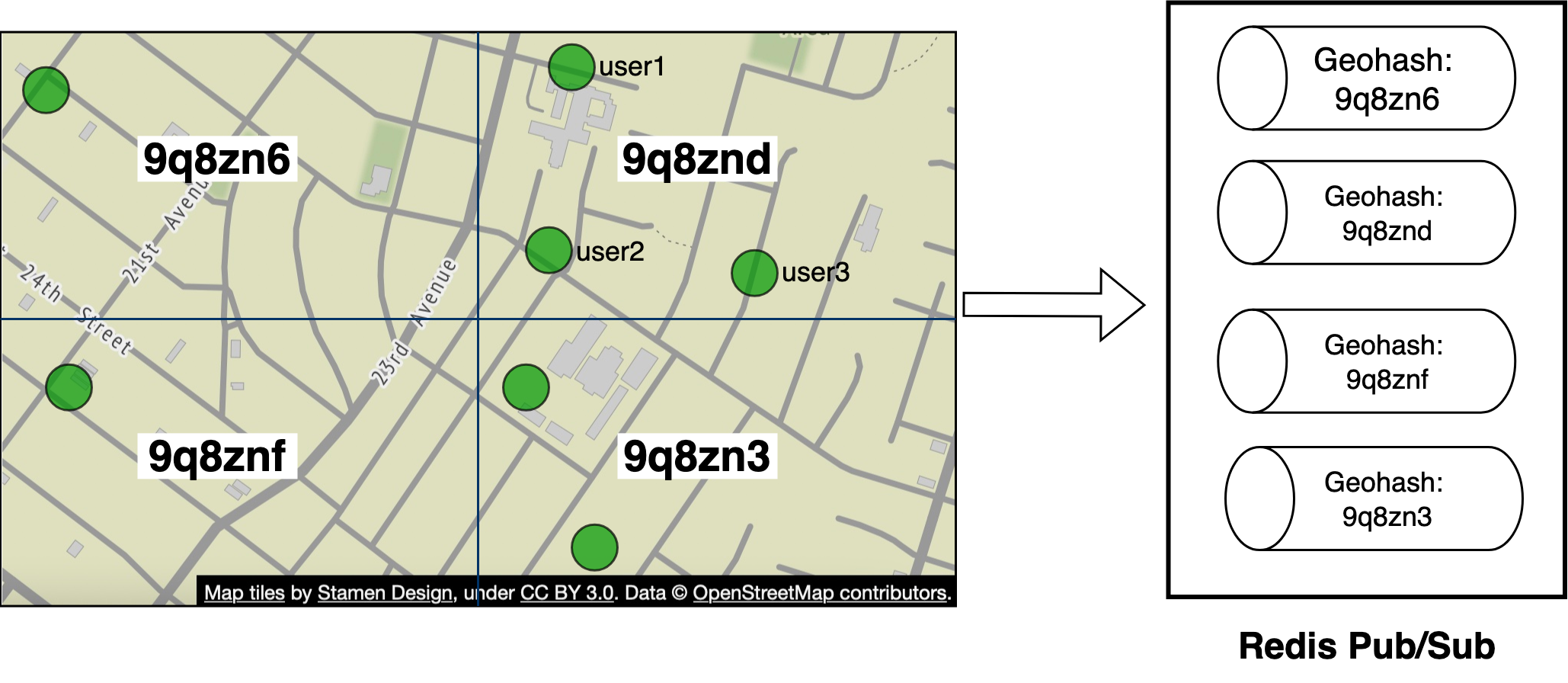
We can also implement a feature whereby a user is shown a random person by computing a Geohash of the user’s location. We can then implement a pool of pub/sub channels by geohash.