Questions
Before we start designing the system, it’s important to start by generating some useful questions. Here are some I came up with
- How many requests are we supposed to serve
- Are there any restrictions on the length of the new url id
- Is there a specific type of url id that we need to adhere to -> Eg. It must be numeric, must be alpha numeric
- Can we allow users to delete and update the Ids / Links of the specific URLs
In short, we have the following features
- The ability to redirect users given a shortened url - (Eg. tinyurl/shortened_url ) to the original url
- The ability to generate a shortened url given a original url which is unique
Of course, we need to make sure that we have a highly available, scalable and fault tolerant considerations. ( Assume that we will be generating ~ 100 million urls per day )
We can estimate that
- With 100 million urls being generated each day, we have around 100 million / 24/ 3600 = 1160 write operations
- Assuming that we have ~ 10x more read operations than write operations, that means we have around 11,600 read operations per second
- Assuming that our URL shortener service will run for ~10 years, we must support 100 million * 365 * 10 = 365 billion records. If we assume that a url will have a max length of 100, then we need approximately 365 * 100 bytes = 36.5 TB of space.
Architecture
We can design our API endpoints as below
api/v1/data/shorten- which takes in a url ( of max length 100 ) and returns a shortened URLapi/v1/shortURL- which takes in a short url and returns a 301 code for HTTP redirection
We also need to make sure to choose a hash function which has enough capacity for the 365 billion records we plan to insert.
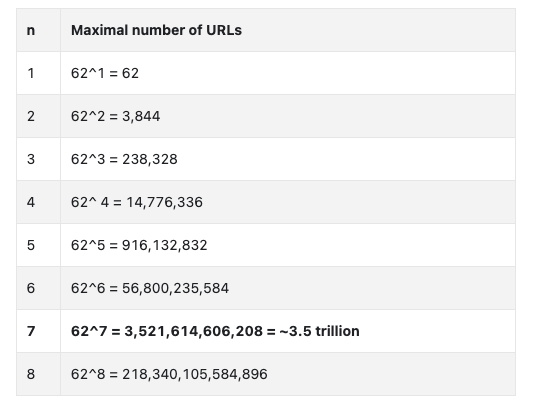
In this case, the minimum size of our hash function must be 7 characters.
Hash Functions
We can utilise a base 62 encoding in order to encode our new URLs. Eg.
-
We insert a new url into our database - it has the database id of 11577.
-
We can calculate it’s short url by transforming its database id from a base 10 encoded value to a base 62 encoded variable ( eg. 11157 -> 2TX )
-
This ensures that we have unique IDs that do not have hash collisions. Note here that IDs are not always 7 characters with this approach - the size of the hash goes up with the value of the ID
However, one of the problems with this approach is that we potentially end up with security concerns from being able to automatically predict what the next short URL is
A potential extension could be Twitter Snowflake which allows us to generate unique IDs in a distributed system.
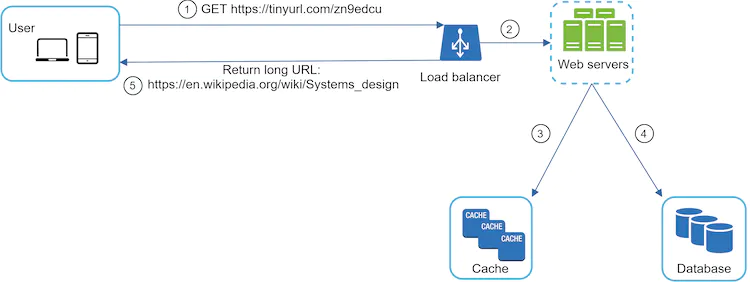
Cache for Lookup
Since we have significantly more reads than writes, we can store a key value pair of <shortURL,longURL> in our database
Talking Points
After we’ve finished working through this, we can look at the following talking points
- Rate Limiting : Which helps us to prevent malicious users from overloading our servers
- Scaling up specific layers (Eg. Cache, Web Server layers that handle APIs)
- Database Sharing/Replication
- Availability, Consistency and Reliability